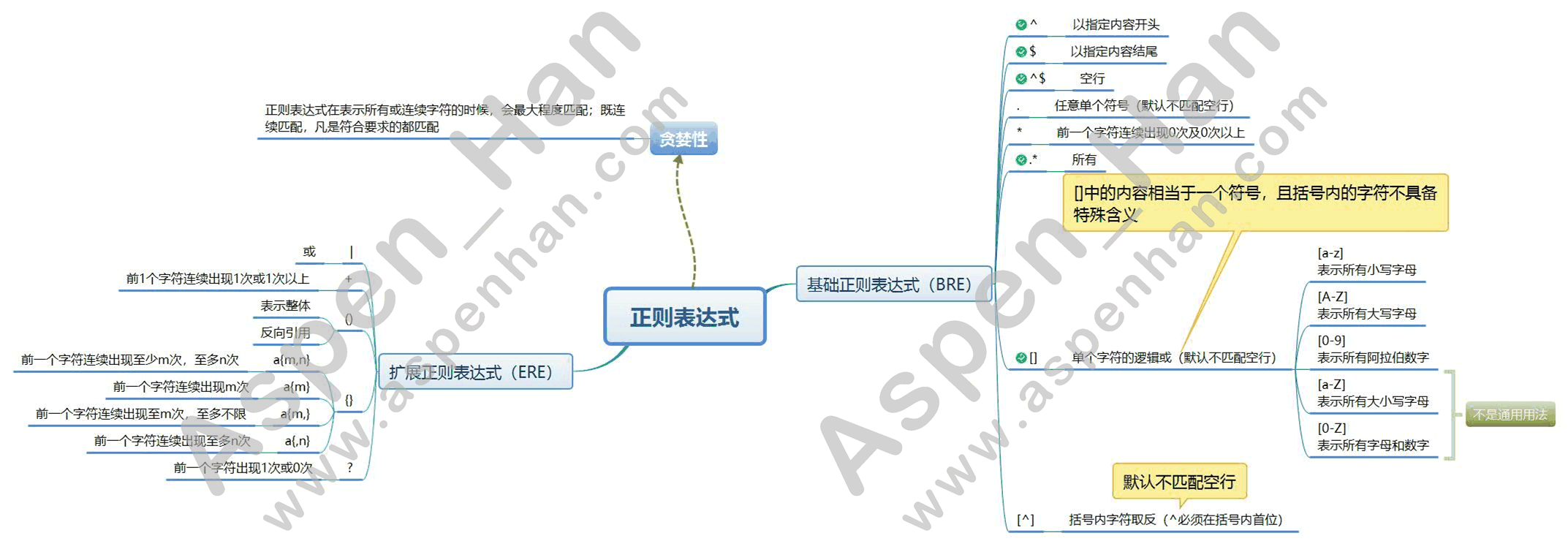
1.正则表达式的特性
| 贪婪性:正则表达式在表示所有或连续字符的时候,会最大程度匹配;既连续匹配,凡是符合要求的都匹配; |
2.基础正则表达式(BRE)
| 符号 | 含义 |
|---|---|
| ^字符 | 以指定内容开头 |
| 字符$ | 以指定内容结尾 |
| ^$ | 空行 |
| . | 任意单个字符(默认不匹配空行) |
| * | 前一个字符连续出现0次及0次以上 |
| .* | 所有 |
| [ ] | 单个字符的逻辑或(默认不匹配空行,括号内的字符不具备特殊含义) |
| [^ ] | 括号内字符取反(^必须在括号内首位,默认不匹配空行) |
| [ ]相当于一个符号(每次匹配1个字符)
[a-z] 表示匹配所有小写字母
[A-Z] 表示匹配所有大写字母
[0-9] 表示匹配所有数字
[a-Z] 表示匹配所有字母(非通用用法)
[0-Z] 表示匹配所有字母和数字(非通用用法)
|
3.扩展正则表达式(ERE)
| 符号 | 含义 |
|---|---|
| | | 或 |
| 字符+ | 前1个字符连续出现1次或1次以上 |
| ( ) | 表示整体或用于sed的后向引用 |
| 字符{ } | 前一个字符重复出现的次数范围 |
| 字符? | 前一个字符出现0次或1次 |
| { }
a{m,n} a连续出现至少m次,至多n次
a{m} a连续出现m次
a{m,} a连续出现至m次,至多不限
a{,n} a连续出现至多n次
|
4.正则表达式与通配符的区别
| 作用 | 支持的命令 | |
|---|---|---|
| 通配符 | 方便我们进行查找文件 | Linux下面大部分命令 |
| 正则 | 方便我们进行过滤(在文件中搜索指定内容) | awk sed grep find 以及开发语言 |
附:思维导图
未完待续...