一、GlusterFS基础
| GlusterFS是由多个存储节点组成的一种开源的分布式文件系统;具有强大的横向扩展能力,可支持PB级存储容量和数千个客户端。相较于NFS,GFS可以避免单点故障并且可动态扩容。GFS具有可扩展性,高性能,高可用性等特点。 |
1. GFS实践
在实际环境中使用GFS
- 副本数一般设置为3
- GFS的节点之间建议使用万兆网络;
- 每一块磁盘作为1个单独的存储单元
- 每个存储节点尽量只存在1个存储单元
- 每个存储节点的第一个存储单元默认端口号为49152
2. GFS工作原理
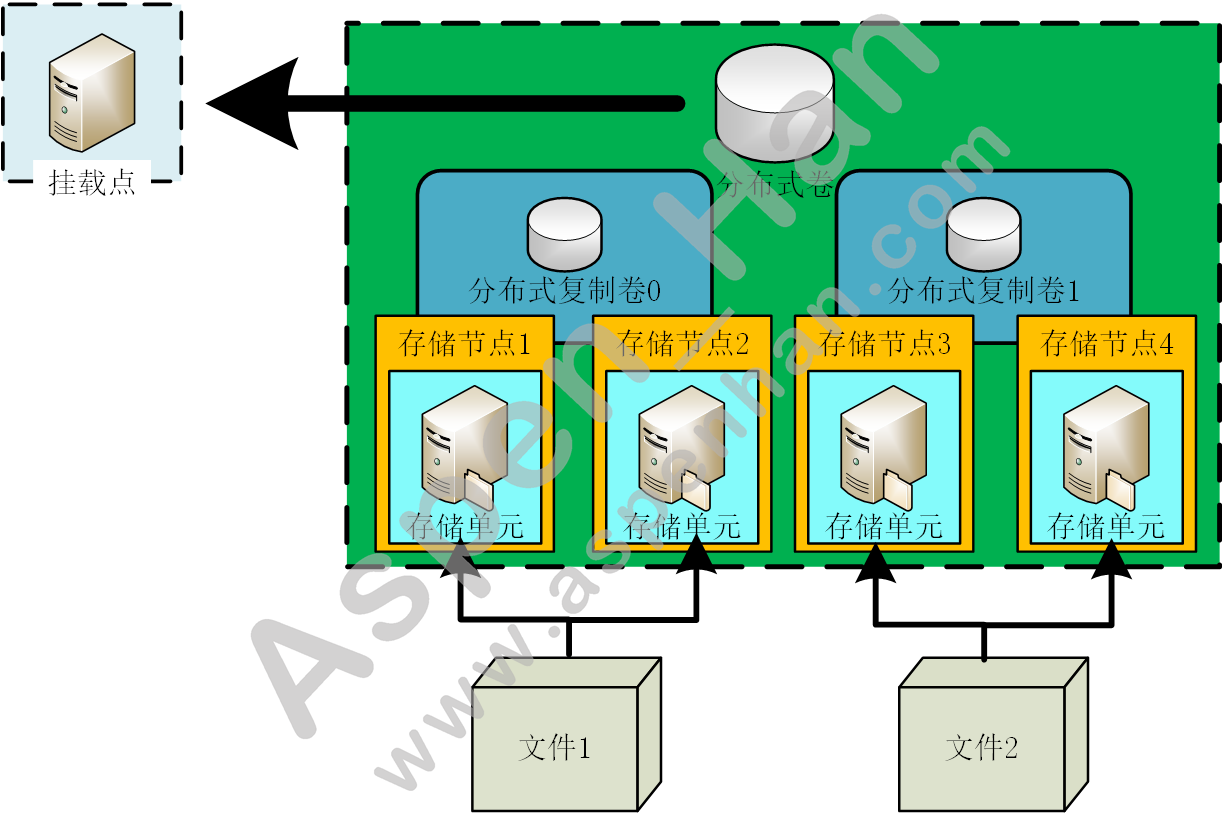
3. GFS安装
step 1 安装GFS
注:所有GFS节点都需要安装GFS服务
|
yum install -y centos-release-gluster6.noarch #安装glusterFS的repo仓库文件 yum install -y glusterfs-server #安装GFS服务端 |
[root@gfs-node1 ~]# ls /etc/yum.repos.d/ | grep -i gluster
[root@gfs-node1 ~]# yum install -y centos-release-gluster6.noarch
......
Installed:
centos-release-gluster6.noarch 0:1.0-1.el7.centos
Dependency Installed:
centos-release-storage-common.noarch 0:2-2.el7.centos
Complete!
[root@gfs-node1 ~]# ls /etc/yum.repos.d/ | grep -i gluster
CentOS-Gluster-6.repo
[root@gfs-node1 ~]# yum install -y glusterfs-server
......
Complete![root@gfs-node2 ~]# yum install -y centos-release-gluster6.noarch && yum install -y glusterfs-server
......
Installed:
centos-release-gluster6.noarch 0:1.0-1.el7.centos
Dependency Installed:
centos-release-storage-common.noarch 0:2-2.el7.centos
Complete!
......
Complete![root@gfs-node3 ~]# yum install -y centos-release-gluster6.noarch && yum install -y glusterfs-server
......
Installed:
centos-release-gluster6.noarch 0:1.0-1.el7.centos
Dependency Installed:
centos-release-storage-common.noarch 0:2-2.el7.centos
Complete!
......
Complete!step 2 启动GFS
|
systemctl start glusterd.service systemctl enable glusterd.service |
[root@gfs-node1 ~]# systemctl enable glusterd.service
Created symlink from /etc/systemd/system/multi-user.target.wants/glusterd.service to /usr/lib/systemd/system/glusterd.service.
[root@gfs-node1 ~]# systemctl start glusterd.service
[root@gfs-node1 ~]# systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2021-07-16 11:29:50 CST; 4s ago
Docs: man:glusterd(8)
Process: 8772 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 8773 (glusterd)
Tasks: 9
Memory: 3.0M
CGroup: /system.slice/glusterd.service
└─8773 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Jul 16 11:29:50 gfs-node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Jul 16 11:29:50 gfs-node1 systemd[1]: Started GlusterFS, a clustered file-system server.[root@gfs-node2 ~]# systemctl enable glusterfsd
Created symlink from /etc/systemd/system/multi-user.target.wants/glusterfsd.service to /usr/lib/systemd/system/glusterfsd.service.
[root@gfs-node2 ~]# systemctl start glusterfsd[root@gfs-node3 ~]# systemctl enable glusterd
Created symlink from /etc/systemd/system/multi-user.target.wants/glusterd.service to /usr/lib/systemd/system/glusterd.service.
[root@gfs-node3 ~]# systemctl start glusterdstep 3 创建存储单元Brick
|
echo '- - -' >/sys/class/scsi_host/host0/scan echo '- - -' >/sys/class/scsi_host/host1/scan echo '- - -' >/sys/class/scsi_host/host2/scan |
[root@gfs-node1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 200M 0 part /boot
├─sda2 8:2 0 1G 0 part [SWAP]
└─sda3 8:3 0 98.8G 0 part /
sr0 11:0 1 4.3G 0 rom
[root@gfs-node1 ~]# echo '- - -' >/sys/class/scsi_host/host0/scan
[root@gfs-node1 ~]# echo '- - -' >/sys/class/scsi_host/host1/scan
[root@gfs-node1 ~]# echo '- - -' >/sys/class/scsi_host/host2/scan
[root@gfs-node1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 200M 0 part /boot
├─sda2 8:2 0 1G 0 part [SWAP]
└─sda3 8:3 0 98.8G 0 part /
sdb 8:16 0 10G 0 disk
sdc 8:32 0 10G 0 disk
sdd 8:48 0 20G 0 disk
sr0 11:0 1 4.3G 0 rom [root@gfs-node2 ~]# systemctl start glusterfsd
[root@gfs-node2 ~]# echo '- - -' >/sys/class/scsi_host/host0/scan
[root@gfs-node2 ~]# echo '- - -' >/sys/class/scsi_host/host1/scan
[root@gfs-node2 ~]# echo '- - -' >/sys/class/scsi_host/host2/scan
[root@gfs-node2 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 200M 0 part /boot
├─sda2 8:2 0 1G 0 part [SWAP]
└─sda3 8:3 0 98.8G 0 part /
sdb 8:16 0 10G 0 disk
sdc 8:32 0 10G 0 disk
sdd 8:48 0 10G 0 disk
sr0 11:0 1 4.3G 0 rom [root@gfs-node3 ~]# echo '- - -' >/sys/class/scsi_host/host0/scan
[root@gfs-node3 ~]# echo '- - -' >/sys/class/scsi_host/host1/scan
[root@gfs-node3 ~]# echo '- - -' >/sys/class/scsi_host/host2/scan
[root@gfs-node3 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 200M 0 part /boot
├─sda2 8:2 0 1G 0 part [SWAP]
└─sda3 8:3 0 98.8G 0 part /
sdb 8:16 0 10G 0 disk
sdc 8:32 0 10G 0 disk
sdd 8:48 0 10G 0 disk
sr0 11:0 1 4.3G 0 rom step 4 创建存储目录
| mkdir 目录 |
[root@gfs-node1 ~]# mkdir -p /GFS/volume{1,2,3}
[root@gfs-node1 ~]# tree /GFS/
/GFS/
├── volume1
├── volume2
└── volume3
3 directories, 0 files[root@gfs-node2 ~]# mkdir -p /GFS/volume{1,2,3}
[root@gfs-node2 ~]# tree /GFS/
/GFS/
├── volume1
├── volume2
└── volume3
3 directories, 0 files[root@gfs-node3 ~]# mkdir -p /GFS/volume{1,2,3}
[root@gfs-node3 ~]# tree /GFS/
/GFS/
├── volume1
├── volume2
└── volume3
3 directories, 0 filesstep 5 存储单元格式化并挂载
|
mkfs.xfs 磁盘名称 mount 磁盘名称 存储目录 |
[root@gfs-node1 ~]# mkfs.xfs /dev/sdb
meta-data=/dev/sdb isize=512 agcount=4, agsize=655360 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=2621440, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@gfs-node1 ~]# mkfs.xfs /dev/sdc
meta-data=/dev/sdc isize=512 agcount=4, agsize=655360 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=2621440, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@gfs-node1 ~]# mkfs.xfs /dev/sdd
meta-data=/dev/sdd isize=512 agcount=4, agsize=1310720 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242880, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@gfs-node1 ~]# mount /dev/sdb /GFS/volume1
[root@gfs-node1 ~]# mount /dev/sdc /GFS/volume2
[root@gfs-node1 ~]# mount /dev/sdd /GFS/volume3[root@gfs-node2 ~]# mkfs.xfs /dev/sdb && mkfs.xfs /dev/sdc && mkfs.xfs /dev/sdd
......
[root@gfs-node2 ~]# mount /dev/sdb /GFS/volume1
[root@gfs-node2 ~]# mount /dev/sdc /GFS/volume2
[root@gfs-node2 ~]# mount /dev/sdd /GFS/volume3[root@gfs-node3 ~]# mkfs.xfs /dev/sdb && mkfs.xfs /dev/sdc && mkfs.xfs /dev/sdd
.....
[root@gfs-node3 ~]# mount /dev/sdb /GFS/volume1
[root@gfs-node3 ~]# mount /dev/sdc /GFS/volume2
[root@gfs-node3 ~]# mount /dev/sdd /GFS/volume3step 6 添加存储资源池
GlusterFS存储资源池中默认只有本机节点。
|
Master节点: gluster pool list #查看存储资源池节点列表 gluster peer probe 节点IP #资源池添加存储节点 gluster peer detach 节点IP #资源池摘除存储节点 |
[root@gfs-node1 ~]# gluster pool list
UUID Hostname State
901c2abd-e2e5-41b5-b1f6-32cd648f612b localhost Connected
[root@gfs-node1 ~]# gluster peer probe 10.0.0.120
peer probe: success.
[root@gfs-node1 ~]# gluster pool list
UUID Hostname State
a97e9ee9-1155-4550-8bd6-4103ba8a3783 10.0.0.120 Connected
901c2abd-e2e5-41b5-b1f6-32cd648f612b localhost Connected
[root@gfs-node1 ~]# gluster peer detach 10.0.0.120
All clients mounted through the peer which is getting detached need to be remounted using one of the other active peers in the trusted storage pool to ensure client gets notification on any changes done on the gluster configuration and if the same has been done do you want to proceed? (y/n) y
peer detach: success
[root@gfs-node1 ~]# gluster pool list
UUID Hostname State
901c2abd-e2e5-41b5-b1f6-32cd648f612b localhost Connected
[root@gfs-node1 ~]# gluster peer probe 10.0.0.130
peer probe: success.
[root@gfs-node1 ~]# gluster peer probe 10.0.0.120
peer probe: success.
[root@gfs-node1 ~]# gluster pool list
UUID Hostname State
8695feaa-3c4e-4d25-86be-1c328bb341ef 10.0.0.130 Connected
a97e9ee9-1155-4550-8bd6-4103ba8a3783 10.0.0.120 Connected
901c2abd-e2e5-41b5-b1f6-32cd648f612b localhost Connected [root@gfs-node2 ~]# gluster pool list
UUID Hostname State
901c2abd-e2e5-41b5-b1f6-32cd648f612b GFS_node1 Connected
8695feaa-3c4e-4d25-86be-1c328bb341ef 10.0.0.130 Connected
a97e9ee9-1155-4550-8bd6-4103ba8a3783 localhost Connected [root@gfs-node3 ~]# gluster pool list
UUID Hostname State
901c2abd-e2e5-41b5-b1f6-32cd648f612b GFS_node1 Connected
a97e9ee9-1155-4550-8bd6-4103ba8a3783 10.0.0.120 Connected
8695feaa-3c4e-4d25-86be-1c328bb341ef localhost Connected step 7 Glusterfs卷管理
存储单元一定是同一资源池内节点上的存储单元
- 分布式卷管理
|
gluster volume create 卷名称 节点IP:/存储单元卷1(目录) 节点IP:/存储单元卷2(目录)... force #创建卷(默认为分布式卷,由多个存储单元共同提供存储容量) gluster volume delete 卷名称 #删除卷(删除卷时,应先取消挂载并停止卷) gluster volume start 卷名称 #启动卷 gluster volume info 卷名称 #查看卷 mount -t glusterfs 节点IP:/卷名称 挂载点 #挂在卷 gluster volume add-brick 卷名称 存储单元卷(目录) force #添加存储单元(存储单元添加成功后,重启卷生效) gluster volume remove-brick 卷名称 存储单元卷(目录) force #删除存储单元(存储单元删除后后,不进行数据迁移) gluster volume stop 卷名称 #停止卷 gluster volume rebalance 卷名称 start #重新均衡卷 |
# 创建卷
[root@gfs-node1 ~]# gluster volume create Young 10.0.0.130:/GFS/volume1 10.0.0.140:/GFS/volume1 force
volume create: Young: success: please start the volume to access data
[root@gfs-node1 ~]# gluster volume info Young
Volume Name: Young
Type: Distribute
Volume ID: 4e997b71-e91d-44d3-9509-439cd798c9ff
Status: Created
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: 10.0.0.130:/GFS/volume1
Brick2: 10.0.0.140:/GFS/volume1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on# 启动卷与挂载卷
[root@gfs-node1 ~]# gluster volume start Young
volume start: Young: success
[root@gfs-node1 ~]# gluster volume info Young
Volume Name: Young
Type: Distribute
Volume ID: 4e997b71-e91d-44d3-9509-439cd798c9ff
Status: Started
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: 10.0.0.130:/GFS/volume1
Brick2: 10.0.0.140:/GFS/volume1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@gfs-node1 ~]# mount -t glusterfs 10.0.0.140:/Young /mnt
shm tmpfs 64M 0 64M 0% /var/lib/docker/containers/d8386a9cb162b834f19cce5be45d970349f7fd7673d6e641a77fa76e50d72d65/shm
/dev/sdb xfs 10G 33M 10G 1% /GFS/volume1
/dev/sdc xfs 10G 33M 10G 1% /GFS/volume2
/dev/sdd xfs 20G 33M 20G 1% /GFS/volume3
tmpfs tmpfs 199M 0 199M 0% /run/user/0
10.0.0.140:/Young fuse.glusterfs 20G 270M 20G 2% /mnt# 添加存储单元
[root@gfs-node1 ~]# gluster volume add-brick Young 10.0.0.120:/GFS/volume1 force
volume add-brick: success
[root@gfs-node1 ~]# df -Th | tail -2
tmpfs tmpfs 199M 0 199M 0% /run/user/0
10.0.0.140:/Young fuse.glusterfs 30G 404M 30G 2% /mnt
[root@gfs-node1 ~]# find /usr/lib/systemd/system/ -iname "i*" -type f -exec cp -t /mnt {} \;
[root@gfs-node1 ~]# ls /mnt/ | xargs -n1 | wc -l
13
[root@gfs-node1 ~]# ls /GFS/volume1 | xargs -n1 | wc -l
10
[root@gfs-node1 ~]# ls /GFS/volume1
initrd-cleanup.service initrd-switch-root.target iprutils.target
initrd-fs.target initrd.target irqbalance.service
initrd-root-fs.target initrd-udevadm-cleanup-db.service
initrd-switch-root.service iprdump.service
[root@gfs-node1 ~]# ssh root@10.0.0.120 "ls /GFS/volume1"
root@10.0.0.120's password:
[root@gfs-node1 ~]# ssh root@10.0.0.130 "ls /GFS/volume1"
root@10.0.0.130's password:
initrd-parse-etc.service
iprinit.service
iprupdate.service
[root@gfs-node1 ~]# ssh root@10.0.0.130 "ls /GFS/volume1 | xargs -n1 | wc -l"
root@10.0.0.130's password:
3
[root@gfs-node1 ~]# gluster volume stop Young
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: Young: success
[root@gfs-node1 ~]# gluster volume start Young
volume start: Young: success
[root@gfs-node1 ~]# gluster volume rebalance Young start
volume rebalance: Young: success: Rebalance on Young has been started successfully. Use rebalance status command to check status of the rebalance process.
ID: bdf1b6cf-2fe2-4b24-ae64-9c72d829e3de
[root@gfs-node1 ~]# ls /GFS/volume1
initrd-root-fs.target initrd-switch-root.target iprdump.service irqbalance.service
initrd-switch-root.service initrd.target iprutils.target
[root@gfs-node1 ~]# ls /GFS/volume1 | xargs -n1 | wc -l
7
[root@gfs-node1 ~]# ssh root@10.0.0.120 "ls /GFS/volume1 "
root@10.0.0.120's password:
initrd-cleanup.service
initrd-fs.target
initrd-parse-etc.service
initrd-udevadm-cleanup-db.service
iprupdate.service
[root@gfs-node1 ~]# ssh root@10.0.0.120 "ls /GFS/volume1 | wc -l"
root@10.0.0.120's password:
5
[root@gfs-node1 ~]# ssh root@10.0.0.130 "ls /GFS/volume1 "
root@10.0.0.130's password:
iprinit.service# 删除存储单元
[root@gfs-node1 ~]# gluster volume remove-brick Young 10.0.0.120:/GFS/volume1 force
Remove-brick force will not migrate files from the removed bricks, so they will no longer be available on the volume.
Do you want to continue? (y/n) y
volume remove-brick commit force: success
[root@gfs-node1 ~]# ssh root@10.0.0.120 "ls /GFS/volume1 "
root@10.0.0.120's password:
initrd-cleanup.service
initrd-fs.target
initrd-parse-etc.service
initrd-udevadm-cleanup-db.service
iprupdate.service
[root@gfs-node1 ~]# gluster volume stop Young
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: Young: success
[root@gfs-node1 ~]# gluster volume start Young
volume start: Young: success
[root@gfs-node1 ~]# umount /mnt/
[root@gfs-node1 ~]# mount -t glusterfs 10.0.0.140:/Young /mnt
[root@gfs-node1 ~]# df -Th | tail -2
tmpfs tmpfs 199M 0 199M 0% /run/user/0
10.0.0.140:/Young fuse.glusterfs 20G 270M 20G 2% /mnt
[root@gfs-node1 ~]# ssh root@10.0.0.120 "ls /GFS/volume1 "
root@10.0.0.120's password:
initrd-cleanup.service
initrd-fs.target
initrd-parse-etc.service
initrd-udevadm-cleanup-db.service
iprupdate.service# 删除存储单元并迁移数据
[root@gfs-node1 ~]# gluster volume remove-brick Young 10.0.0.130:/GFS/volume1 force
Remove-brick force will not migrate files from the removed bricks, so they will no longer be available on the volume.
Do you want to continue? (y/n) y
volume remove-brick commit force: success
[root@gfs-node1 ~]# ls /mnt/
initrd-cleanup.service initrd-parse-etc.service iprinit.service
initrd-fs.target initrd-udevadm-cleanup-db.service iprupdate.service
[root@gfs-node1 ~]# scp 10.0.0.130:/GFS/volume1/* /mnt/
root@10.0.0.130's password:
initrd-root-fs.target 100% 526 234.0KB/s 00:00
initrd-switch-root.service 100% 644 348.4KB/s 00:00
initrd-switch-root.target 100% 691 310.7KB/s 00:00
initrd.target 100% 671 255.4KB/s 00:00
iprdump.service 100% 184 99.9KB/s 00:00
iprutils.target 100% 173 25.7KB/s 00:00
irqbalance.service 100% 209 94.4KB/s 00:00
[root@gfs-node1 ~]# ls /mnt/
initrd-cleanup.service initrd-switch-root.service iprdump.service irqbalance.service
initrd-fs.target initrd-switch-root.target iprinit.service
initrd-parse-etc.service initrd.target iprupdate.service
initrd-root-fs.target initrd-udevadm-cleanup-db.service iprutils.target
[root@gfs-node1 ~]# ls /GFS/volume1/
initrd-cleanup.service initrd-parse-etc.service iprupdate.service
initrd-fs.target initrd-udevadm-cleanup-db.service
[root@gfs-node1 ~]# ssh root@10.0.0.120 'ls /GFS/volume1'
root@10.0.0.120's password:
initrd-root-fs.target
initrd-switch-root.service
initrd-switch-root.target
initrd.target
iprdump.service
iprinit.service
iprutils.target
irqbalance.service# 删除卷
[root@gfs-node1 ~]# umount /mnt/
[root@gfs-node1 ~]# gluster volume stop Young
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: Young: success
[root@gfs-node1 ~]# gluster volume delete Young
Deleting volume will erase all information about the volume. Do you want to continue? (y/n) y
volume delete: Young: success
[root@gfs-node1 ~]# ls /GFS/volume1/
initrd-cleanup.service initrd-parse-etc.service iprupdate.service
initrd-fs.target initrd-udevadm-cleanup-db.service
[root@gfs-node1 ~]# ssh root@10.0.0.120 'ls /GFS/volume1'
root@10.0.0.120's password:
initrd-root-fs.target
initrd-switch-root.service
initrd-switch-root.target
initrd.target
iprdump.service
iprinit.service
iprutils.target
irqbalance.service
[root@gfs-node1 ~]# gluster volume info Young
Volume Young does not exist- 分布式复制卷管理
|
gluster volume create 卷名称 replica n 节点IP:/存储单元卷 节点IP:/复制单元卷 ... IP:/复制单元卷[n-1] #创建分布式复制卷 gluster volume add-brick 卷名称 节点IP:/存储单元卷 节点IP:/复制单元卷 ... IP:/复制单元卷[n-1] force #添加存储单元(存储单元添加成功后,重启卷生效) |
# 创建分布式复制卷
[root@gfs-node1 ~]# gluster volume create Young replica 3 10.0.0.120:/GFS/volume1 10.0.0.130:/GFS/volume1 10.0.0.140:/GFS/volume1 10.0.0.120:/GFS/volume2 10.0.0.130:/GFS/volume2 10.0.0.140:/GFS/volume3 force
volume create: Young: success: please start the volume to access data
[root@gfs-node1 ~]# gluster volume start Young
volume start: Young: success
[root@gfs-node1 ~]# gluster volume info Young
Volume Name: Young
Type: Distributed-Replicate
Volume ID: c2d52236-894b-41eb-b591-56b020793df0
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 3 = 6
Transport-type: tcp
Bricks:
Brick1: 10.0.0.120:/GFS/volume1
Brick2: 10.0.0.130:/GFS/volume1
Brick3: 10.0.0.140:/GFS/volume1
Brick4: 10.0.0.120:/GFS/volume2
Brick5: 10.0.0.130:/GFS/volume2
Brick6: 10.0.0.140:/GFS/volume3
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
[root@gfs-node1 ~]# df -Th | tail -1
10.0.0.120:/Young fuse.glusterfs 20G 270M 20G 2% /mnt# 分布式复制卷-数据存储
[root@gfs-node1 ~]# find /usr/lib/systemd/system/ -iname "t*" -type f -exec cp -t /mnt {} \;
[root@gfs-node1 ~]# ls /mnt/
tcsd.service timers.target tmp.mount tuned.service
teamd@.service time-sync.target trace-cmd.service
[root@gfs-node1 ~]# tree /GFS/
/GFS/
├── volume1
│ ├── tcsd.service
│ ├── teamd@.service
│ ├── timers.target
│ └── trace-cmd.service
├── volume2
│ ├── time-sync.target
│ ├── tmp.mount
│ └── tuned.service
└── volume3
3 directories, 7 files
[root@gfs-node1 ~]# ssh root@10.0.0.120 tree /GFS
root@10.0.0.120's password:
/GFS
├── volume1
│ ├── tcsd.service
│ ├── teamd@.service
│ ├── timers.target
│ └── trace-cmd.service
├── volume2
│ ├── time-sync.target
│ ├── tmp.mount
│ └── tuned.service
└── volume3
3 directories, 7 files
[root@gfs-node1 ~]# ssh root@10.0.0.130 tree /GFS
root@10.0.0.130's password:
/GFS
├── volume1
│ ├── tcsd.service
│ ├── teamd@.service
│ ├── timers.target
│ └── trace-cmd.service
├── volume2
│ ├── time-sync.target
│ ├── tmp.mount
│ └── tuned.service
└── volume3
3 directories, 7 files# 分布式复制卷-添加存储节点
[root@gfs-node1 ~]# gluster volume add-brick Young 10.0.0.120:/GFS/volume3 10.0.0.130:/GFS/volume3 10.0.0.140:/GFS/volume3 force
volume add-brick: success
[root@gfs-node1 ~]# gluster volume stop Young
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: Young: success
[root@gfs-node1 ~]# gluster volume start Young
volume start: Young: success
[root@gfs-node1 ~]# gluster volume rebalance Young start
volume rebalance: Young: success: Rebalance on Young has been started successfully. Use rebalance status command to check status of the rebalance process.
ID: b4880bd0-b468-431e-9827-14b95c9d75a7
[root@gfs-node1 ~]# tree /GFS/
/GFS/
├── volume1
│ ├── time-sync.target
│ └── tmp.mount
├── volume2
│ ├── tcsd.service
│ ├── teamd@.service
│ ├── timers.target
│ └── trace-cmd.service
└── volume3
└── tuned.service
3 directories, 7 files